
Really wicked/lame idea for compression
category: general [glöplog]
Last night I thought about compression: What would be the ultimate way of compression something? Then I came up with this:
Pi has an infinite amount of unique numbers. It is possible to find out what the n-th value in a row is when using hexadecimals (google for pi hex or something like that). So if you took a chunk of a few hundred bytes and started to search through Pi for it, you would eventually find it. Each chunk will be saved as an index and a length. The decompression should be very simple and quite fast, and one top of that, compressing the indexes and the lengths could also give results.
Of course, you could end up having to way aeons for your compressor to find the matching indexes, but it is still a fun idea.
Any other "super compression" ideas that could be automated like that?
Pi has an infinite amount of unique numbers. It is possible to find out what the n-th value in a row is when using hexadecimals (google for pi hex or something like that). So if you took a chunk of a few hundred bytes and started to search through Pi for it, you would eventually find it. Each chunk will be saved as an index and a length. The decompression should be very simple and quite fast, and one top of that, compressing the indexes and the lengths could also give results.
Of course, you could end up having to way aeons for your compressor to find the matching indexes, but it is still a fun idea.
Any other "super compression" ideas that could be automated like that?

dear god, please hand lord graga a goddamn math/probability theory book and make him read.

and then people will start to write their rants about the fucking extralong precalculation of these new kind of intros...
and then coders will start to write their rants about the fucking extralow compression ratio of your new kind of compression...
and then pouet will become a place of perdition for every still-alive-but-half-dead sceners...
(as if any of these things above it's not already true)
and then coders will start to write their rants about the fucking extralow compression ratio of your new kind of compression...
and then pouet will become a place of perdition for every still-alive-but-half-dead sceners...
(as if any of these things above it's not already true)
It is not really probability if it is bound to happend eventually, is it? :P
hey, if you search hard enough inside pi you can find , not only all the works shakespeare, but also all the porn - in perfect DVD quality format - ever directed and not directed yet. How about that..
Lord: theoretically everything is correct, but tell me why do you assume that the chunk will take more bytes than index itself? Well let's take for example 44444 (we'll store it in two bytes for simplicity) If I'm correct this subsequence of PI lies near 800000'th number after the dot. So you'll need more than to bytes to store it. Of course taking bigger chunks will result in much much bigger indices.
But I must say that the idea is theoretically very pretty :)
But I must say that the idea is theoretically very pretty :)

My new demo starts at 21123621438763423746435473895743598743598437593485743985
7498574398574385743955445543534534554423454354354545455
number but I won't tell You the length :)
7498574398574385743955445543534534554423454354354545455
number but I won't tell You the length :)
Okay, go away, I'm just taking my brainfarts for a walk.
Quote:
What's the probability of it happening while you're alive?It is not really probability if it is bound to happend eventually, is it? :P
I have a "probability and statistic" exam next week... ouch.

graga: you can encode theoretically everything with a natural number, for computer science / mathematics this is called godel number.
you could for example encode the same way a program generating your data, but it's mostly probable that the encoding of indexes or godel number would be bigger than your data.
so: i second bonzaj =)
you could for example encode the same way a program generating your data, but it's mostly probable that the encoding of indexes or godel number would be bigger than your data.
so: i second bonzaj =)
navis: what's the offset of that pron in there? :)

As makc said, that is "the problem" with your method.
And also, there is no way for a lossless "magic compressor", where all the inputs generates a less big output. It is very easy to understand by the pingeonhole teorem. So, suppose a compressor that for any input of n bits generates a n-1 bits of output. Then, you will have 2^n possible inputs and a maximum of 2^(n-1) outputs. By the pingeonhole, more than one output will be the same for different inputs, so it will be impossible to determinate wich was the original input (without more information).
And also, there is no way for a lossless "magic compressor", where all the inputs generates a less big output. It is very easy to understand by the pingeonhole teorem. So, suppose a compressor that for any input of n bits generates a n-1 bits of output. Then, you will have 2^n possible inputs and a maximum of 2^(n-1) outputs. By the pingeonhole, more than one output will be the same for different inputs, so it will be impossible to determinate wich was the original input (without more information).
pi-wee compression scheme!
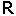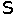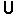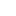
What I usually do, is I take a sequence of bits and slice it it half. Then I XOR these two sequences to produce a new sequence half the length. I do this repeatedly until I have everything compressed into a single bit.













Just throw away every second byte. Keep doing this until your file is zero bytes.
To recreate the file from the zero byte file, just do whatever you did to create the file in the first place, again.
To recreate the file from the zero byte file, just do whatever you did to create the file in the first place, again.
approximate all data with an elephant

mmm some french-speaking mofo with too much free time should translate those wicked shadok mottos into english, they are worth it :>
Add all the bytes together to one huge integer and then divide it by 100.

I recall a Useless Utility Compo entry (TG92 I think?) that would magically compress any file to one byte.

Graga: Your idea is insane but you could still try to sell it to former Philips president Roel Pieper, after all he fell for it before.
Read more about the Stick of Jan Sloot here :-)
Read more about the Stick of Jan Sloot here :-)

watched too much of this? http://www.imdb.com/title/tt0138704/

Yeah, awesome movie :-)
Also, don't forget this
(Thanks Okkie, for posting that link once on irc, ofcourse only you could come up with obscure videos like that :-)
Also, don't forget this
(Thanks Okkie, for posting that link once on irc, ofcourse only you could come up with obscure videos like that :-)
A little search toy to check that graga's idea doesent work (search for 1337 in pi).
quite interesting site btw.
quite interesting site btw.