
Amiga 500: New blitter c2p routine implemented. Need help to speedtest
category: general [glöplog]
Table effect Winuae Timings. Using the latest SMC loops found on ada site.
Note: In the latest winuae version from march there is a correction in the cia timer.
amiga 500 1 meg chipmem. (cycle excact cpu and blitter)
How many big screen in 25 fps 2x2.
CPU merge: 747 - (320*166)
BLITTER: 527 + blitter - (320*236)
In theory the blitterpass should run in every free buscycle. but I am not able to confirm it in winuae.
Note: In the latest winuae version from march there is a correction in the cia timer.
amiga 500 1 meg chipmem. (cycle excact cpu and blitter)
How many big screen in 25 fps 2x2.
CPU merge: 747 - (320*166)
BLITTER: 527 + blitter - (320*236)
In theory the blitterpass should run in every free buscycle. but I am not able to confirm it in winuae.
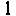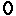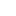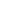
The cpu only version uses around 15 cycles extra pr word written to memory. The blitterpass use 8 cycles pr word. (but since the blitter is multitasking with the cpu should be free (in theory) )
yes that looks good... my speedtest some days ago was not correct... forgot to remove some effect code ;))
Time for another update. :D
The source I have distributed is really lame because the vbl wait routine is hammering the chipmem and stealing bus cycles from the blitter. Anyway, if you are skilled enough to use this c2p, you probobly know how to use it optimal. :D The blitter passes should be placed in a blitter interupt. Instead of a vblwait you simply wait for blitter finished. in the wait loop you place some cpu code that won't se buscycles.. (muls??):D
.
I have been traveling around in Thailand now and got little time to work on my engine. Problobly I wont finish anything for breakpoint. :( The txture mapper is divs free now and damn fast.(less than 256 bytes) ;)
"faster than copyspeed" !!!!
'
he-he
Probobly this c2p teqnique will run damn fast on a amiga 1200 in 1x1. (by using med res.) (640x200) Fullscreen 1x1 txturemapping in 25 fps should be possible..
The source I have distributed is really lame because the vbl wait routine is hammering the chipmem and stealing bus cycles from the blitter. Anyway, if you are skilled enough to use this c2p, you probobly know how to use it optimal. :D The blitter passes should be placed in a blitter interupt. Instead of a vblwait you simply wait for blitter finished. in the wait loop you place some cpu code that won't se buscycles.. (muls??):D
.
I have been traveling around in Thailand now and got little time to work on my engine. Problobly I wont finish anything for breakpoint. :( The txture mapper is divs free now and damn fast.(less than 256 bytes) ;)
"faster than copyspeed" !!!!
'
he-he
Probobly this c2p teqnique will run damn fast on a amiga 1200 in 1x1. (by using med res.) (640x200) Fullscreen 1x1 txturemapping in 25 fps should be possible..
or maybe just put an "stop $0200" in the waitloop before checking if the c2p has finished, so that you really just wait for an interrupt without anymore bus accesses.
nice idea. Another solution is to set the "blitter nasty" bit in $dff096 and then clear it when the blitter pass is finished..
.
Memory is my enemy since most of my optimalisations involves precalculation. But as Bill Gates once said 640kb should be enough for everybody. I have 1 meg!
C64 coders will say demos should be realtime. but faster thatn copyspeed involves precalculation.. he-he.
Today I have implemented a recursive lz-hoffman decoder in asm. Now i need to code the encoder. :-( Stupid work really...
I need a cruncher to be able to crunch my precalculations realtime.
Thailand is getting really hot now (april is the hottest month of the year.) 30 degrees ++ in my house, hard to consentrate. No aircondition, just a fan.
.
Memory is my enemy since most of my optimalisations involves precalculation. But as Bill Gates once said 640kb should be enough for everybody. I have 1 meg!
C64 coders will say demos should be realtime. but faster thatn copyspeed involves precalculation.. he-he.
Today I have implemented a recursive lz-hoffman decoder in asm. Now i need to code the encoder. :-( Stupid work really...
I need a cruncher to be able to crunch my precalculations realtime.
Thailand is getting really hot now (april is the hottest month of the year.) 30 degrees ++ in my house, hard to consentrate. No aircondition, just a fan.
BTW: wasn't there some sort of military coup recently ??

Here is a little taste of my decruncher routine with comments in Norwegian.
;Mc68020 ++
CODEPORN:
;- Huffman treet lagret i minne som et Komplett binært tre
;- finner endenoder ved å sjekke om child nodene or-et sammen == 0
HOFFMANDECRUNCH:
; lea pakkdata,a0
; lea outputbuffer,a1
; lea huffmantree,a2
move.b (a0)+,d0 ;8 bit
move.l #16000-1,d5 ;antallbytes som skal pakkes opp
.byteloop
moveq.l #0,d5 ;bitteller
moveq.l #0,d6 ;posteller.
moveq.l #1,d7 ;n-teller
.treloop
add.b d0,d0 ;get leftbit.
bcc.b .venstre
addq.l #1,d6
.venstre
add.l d7,d6 ;finn riktig pos.
add.l d7,d7 ;n*2
addq.l #1,d5
cmp.b #8,d5
bne.b .over
move.b (a0)+,d0 ;hent mer data.
moveq.l #0,d5
.over
;sjekk om childnodene er tomme (har vi en ende node)
move.l d6,d3
move.b (a2,d6.l*2),d0
or.b 1(a2,d6.l*2),d0
beq.b .treloop
move.b (a2,d6.l),(a1)+
dbf d5,.byteloop
rts
;Mc68020 ++
CODEPORN:
;- Huffman treet lagret i minne som et Komplett binært tre
;- finner endenoder ved å sjekke om child nodene or-et sammen == 0
HOFFMANDECRUNCH:
; lea pakkdata,a0
; lea outputbuffer,a1
; lea huffmantree,a2
move.b (a0)+,d0 ;8 bit
move.l #16000-1,d5 ;antallbytes som skal pakkes opp
.byteloop
moveq.l #0,d5 ;bitteller
moveq.l #0,d6 ;posteller.
moveq.l #1,d7 ;n-teller
.treloop
add.b d0,d0 ;get leftbit.
bcc.b .venstre
addq.l #1,d6
.venstre
add.l d7,d6 ;finn riktig pos.
add.l d7,d7 ;n*2
addq.l #1,d5
cmp.b #8,d5
bne.b .over
move.b (a0)+,d0 ;hent mer data.
moveq.l #0,d5
.over
;sjekk om childnodene er tomme (har vi en ende node)
move.l d6,d3
move.b (a2,d6.l*2),d0
or.b 1(a2,d6.l*2),d0
beq.b .treloop
move.b (a2,d6.l),(a1)+
dbf d5,.byteloop
rts
the "move.l #16000-1,d5" hurts my sensitive eyes. :D

Dodge: Yes, but I feel pretty safe here. Although I had a shooting incident right outside my house here the other thai. There are 2 bars in my street wich creates some noice at night. I woke up when somebody where shouting at eachother outside my house. I looked out the window and saw to thai men fighting with a crowd. Then I heard a gun-shot. Just a warning shot this time, and the crowd split...
Well I have lived 1,5 years in california close to Oakland, so I guess I am used to ut. he-he
StingRay: The source is not finished yet. hardcoding is just for test purposes. Actually I plan to make another 4k cruncher. 1 section pc relative code packed with lz hoffman. I think the cruncher Azure wrote many years ago is the most common used today. The lz decrunch pass is also very small and smooth, but I am not sure if it will pack bether.
.
Would be fun to resource one one of loaderrors masterpieces (4k) replace the cruncher, and remove some more bytes. Yeap, Loaderror is a lazy coder. he-he
Well I have lived 1,5 years in california close to Oakland, so I guess I am used to ut. he-he
StingRay: The source is not finished yet. hardcoding is just for test purposes. Actually I plan to make another 4k cruncher. 1 section pc relative code packed with lz hoffman. I think the cruncher Azure wrote many years ago is the most common used today. The lz decrunch pass is also very small and smooth, but I am not sure if it will pack bether.
.
Would be fun to resource one one of loaderrors masterpieces (4k) replace the cruncher, and remove some more bytes. Yeap, Loaderror is a lazy coder. he-he
sp: actually, I didn't mean the 16000-1 part, I complained about the move.l there. :P
About Loaderror's 4k's, I had an awful amount of fun removing a lot of bytes from this one. :) Which is btw still the 4k with my favourite soundtrack, Loady might be lazy but he knows how to design and compose. :-)
About Loaderror's 4k's, I had an awful amount of fun removing a lot of bytes from this one. :) Which is btw still the 4k with my favourite soundtrack, Loady might be lazy but he knows how to design and compose. :-)
add.b d0,d0 ;get leftbit.
bcc.b .venstre
addq.l #1,d6
.venstre:
this can be optimised with addx.l if you have a data register to spare:
add.b d0,d0 ;get leftbit.
addx.l d4,d6
(d4 should be zero ofcourse)
bcc.b .venstre
addq.l #1,d6
.venstre:
this can be optimised with addx.l if you have a data register to spare:
add.b d0,d0 ;get leftbit.
addx.l d4,d6
(d4 should be zero ofcourse)
cmp.b #8,d5
bne.b .over
move.b (a0)+,d0 ;hent mer data.
moveq.l #0,d5
.over
could be changed to:
and.b #8-1,d5
bne.b .over
move.b (a0)+,d0
.over
I think. Hmm, also, did you test the code yet? Because, there's move.l #16000-1,d5 and in your decrunch loop there's moveq #0,d5 etc. :-)
bne.b .over
move.b (a0)+,d0 ;hent mer data.
moveq.l #0,d5
.over
could be changed to:
and.b #8-1,d5
bne.b .over
move.b (a0)+,d0
.over
I think. Hmm, also, did you test the code yet? Because, there's move.l #16000-1,d5 and in your decrunch loop there's moveq #0,d5 etc. :-)
The code is not tested yet and not finished, since I haven't written the decruncher It's hard to test it. But hey, nice to get my code optimized. Keep working guys!! The addx trick is really nice.
Atari and Amiga coders Optimize, PC coders buy new hardware!
.
re Stingray,
Respect to Loaderror who have artistic talent, visual and musical and he is a pretty good coder too. I like to watch all the newest Ephidrena Releases.
Atari and Amiga coders Optimize, PC coders buy new hardware!
.
re Stingray,
Respect to Loaderror who have artistic talent, visual and musical and he is a pretty good coder too. I like to watch all the newest Ephidrena Releases.
Why not... :)
HOFFMANDECRUNCH:
; lea pakkdata,a0
; lea outputbuffer,a1
; lea huffmantree,a2
move.b (a0)+,d0 ;8 bit
move.w #16000-1,d4 ;antallbytes som skal pakkes opp
.byteloop
moveq.l #-128,d5 ;bitteller
moveq.l #0,d6 ;posteller.
moveq.l #1,d7 ;n-teller
.treloop
add.b d0,d0 ;get leftbit.
bcc.b .venstre
addq.l #1,d6
.venstre
add.l d7,d6 ;finn riktig pos.
add.l d7,d7 ;n*2
rol.b #1,d5
bpl.b .over
move.b (a0)+,d0 ;hent mer data.
.over
;sjekk om childnodene er tomme (har vi en ende node)
tst.w (a2,d6.l*2)
beq.b .treloop
move.b (a2,d6.l),(a1)+
subq.w #1,d4
bne.b .byteloop
rts
HOFFMANDECRUNCH:
; lea pakkdata,a0
; lea outputbuffer,a1
; lea huffmantree,a2
move.b (a0)+,d0 ;8 bit
move.w #16000-1,d4 ;antallbytes som skal pakkes opp
.byteloop
moveq.l #-128,d5 ;bitteller
moveq.l #0,d6 ;posteller.
moveq.l #1,d7 ;n-teller
.treloop
add.b d0,d0 ;get leftbit.
bcc.b .venstre
addq.l #1,d6
.venstre
add.l d7,d6 ;finn riktig pos.
add.l d7,d7 ;n*2
rol.b #1,d5
bpl.b .over
move.b (a0)+,d0 ;hent mer data.
.over
;sjekk om childnodene er tomme (har vi en ende node)
tst.w (a2,d6.l*2)
beq.b .treloop
move.b (a2,d6.l),(a1)+
subq.w #1,d4
bne.b .byteloop
rts

And beq.b .treloop should of couse be bne.b .treloop.
And use teh addx trick for speed.
And. Put this
rol.b #1,d5
bpl.b .over
move.b (a0)+,d0 ;hent mer data.
.over
Right after .treloop, and init d5 to 64 instead of 128 (should be outside of byteloop too), saves you from loading the first byte.
And. Put this
rol.b #1,d5
bpl.b .over
move.b (a0)+,d0 ;hent mer data.
.over
Right after .treloop, and init d5 to 64 instead of 128 (should be outside of byteloop too), saves you from loading the first byte.
Cute. :D
there is a tiny bug though. :D
"C64 coders will say demos should be realtime"
C64 coders says, what you do is teh real coding, directx is for sissys ;)
C64 coders says, what you do is teh real coding, directx is for sissys ;)

Quote:
Actually I plan to make another 4k cruncher. 1 section pc relative code packed with lz hoffman. I think the cruncher Azure wrote many years ago is the most common used today. The lz decrunch pass is also very small and smooth, but I am not sure if it will pack bether.
You might want to take a look at this one, which has also been used by a couple of people for some years. It has lots of weird options - give it a ? to get some help, and then experiment with option values. Use the MINI option for 4ks (requires that there is just one non-empty section and no relocations).
Pezac and I did a small comparison against Azure's packer on his Solskogen 4k, and mine fared a little better.
Anyway, I am working on a new packer, with an entirely new algorithm (LZ/CM hybrid), which shaves off another 100 bytes on a 4k, typically. I should at least have a prototype ready for Breakpoint (I will need it myself by then).

Now it is beautiful!
hasselhuffman:
move.w #16000-1,d4
moveq #1,d5
moveq #0,d3
.b moveq #0,d6
moveq #1,d7
.t ror.l #1,d5
bpl.b .o
move.l (a0)+,d0
.o add.l d0,d0
addx.l d3,d6
add.l d7,d6
add.l d7,d7
tst.w (a2,d6.l*2)
bne.b .t
move.b (a2,d6.l),(a1)+
subq.w #1,d4
bne.b .b
rts
hasselhuffman:
move.w #16000-1,d4
moveq #1,d5
moveq #0,d3
.b moveq #0,d6
moveq #1,d7
.t ror.l #1,d5
bpl.b .o
move.l (a0)+,d0
.o add.l d0,d0
addx.l d3,d6
add.l d7,d6
add.l d7,d7
tst.w (a2,d6.l*2)
bne.b .t
move.b (a2,d6.l),(a1)+
subq.w #1,d4
bne.b .b
rts
@Blueberry
Cool! I've been wanting to try out your packer for a while. Thanks for posting a link to it :)
Cool! I've been wanting to try out your packer for a while. Thanks for posting a link to it :)
@Blueberry
Thank you very much for release your packer. Please, post a link to the documentation, if exists, or elaborate a little bit about the arguments.
I have found the list of arguments with "?", and tested the cruncher changing options (is indeed a very good packer even just using the default options) but would be good if you explain a little bit those obscure arguments.
I probably will use this packer in my next 4k intro. (Breakpoint?, Euskal? who knows?)
@sp^contraz
Turn the fan on and keep on coding! ;)
Thank you very much for release your packer. Please, post a link to the documentation, if exists, or elaborate a little bit about the arguments.
I have found the list of arguments with "?", and tested the cruncher changing options (is indeed a very good packer even just using the default options) but would be good if you explain a little bit those obscure arguments.
I probably will use this packer in my next 4k intro. (Breakpoint?, Euskal? who knows?)
@sp^contraz
Turn the fan on and keep on coding! ;)

Ham: work out the options yourself, that's the fun part of using Blueberry's packer. :) It's fun to try to find the best options. =) There's no documentation as far as I know but it's not hard to use anyway. Perfect coder's toy. :)