
Amiga 500: New blitter c2p routine implemented. Need help to speedtest
category: general [glöplog]
@Stingray
I manage to save 400 bytes repacking my old 4k intro Proton with just the standard options. I'm very happy but I think that Blueberry could explain a little bit about this cruncher. For example: how works? how many bytes long is the depacking routine? needs 68020 or just use plain 68000 code? People wants to know! ;)
I manage to save 400 bytes repacking my old 4k intro Proton with just the standard options. I'm very happy but I think that Blueberry could explain a little bit about this cruncher. For example: how works? how many bytes long is the depacking routine? needs 68020 or just use plain 68000 code? People wants to know! ;)

Well, I use his cruncher for quite some time already (thanks Blueberry :D) and I never felt like I would need any docs, it's was "try and check if you can squeeze some more bytes" for me and I always loved that. :) The decruncher needs 020+, that much I can tell you. :)

I love this cruncher. Works good even for 64k intros.
Thank you again, Blueberry! :D
Thank you again, Blueberry! :D
About the decrunch headers:
The normal decrunch header is 340 bytes. The MINI header is 168 bytes. Both headers work on 68000.
The normal header checks the kickstart version and only clears caches if kickstart is 2.0 or above, thus it works on all kickstart versions. The MINI header requires kickstart 2.0 or higher.
The normal header saves A0 and D0 and thus preserves commandline arguments. The MINI header doesn't.
For a 4k, I usually use something like MINI 30 ML 30 MD 300 RSW2 900. But it all depends on your data. As StingRay says, just play around with the options. Many of them don't have any easily explainable meaning. :)
The normal decrunch header is 340 bytes. The MINI header is 168 bytes. Both headers work on 68000.
The normal header checks the kickstart version and only clears caches if kickstart is 2.0 or above, thus it works on all kickstart versions. The MINI header requires kickstart 2.0 or higher.
The normal header saves A0 and D0 and thus preserves commandline arguments. The MINI header doesn't.
For a 4k, I usually use something like MINI 30 ML 30 MD 300 RSW2 900. But it all depends on your data. As StingRay says, just play around with the options. Many of them don't have any easily explainable meaning. :)

Quote:
I probably will use this packer in my next 4k intro. (Breakpoint?, Euskal? who knows?)
Breakpoint! ;)
Umm yeah, it indeed doesn't need 020+, sorry Blueberry. :) I thought you used some bitfield commands there, don't ask me why. :-) Might have to do with the fact that I never used your cruncher for stuff that runs on 68000. ;)
@Blueberry
Thank you for your explanations. I hope to see you at Breakpoint! ;)
Thank you for your explanations. I hope to see you at Breakpoint! ;)
re, Doom^IRIS
Tnx for helping me optimize. I restructured the hoffman table and removed more bytes. Now the loop is only 32 bytes. This routine is ideal for 4k decrunching, but since the hoffman table is a complete binary tree, it takes n! memory where n is the biggest hoffman code in the crunch.
SP_HOFFMANDECRUNCH:
moveq #1,d5
moveq #0,d3
.b moveq #1,d6
.t ror.l #1,d5
bpl.b .o
move.l (a0)+,d0
.o add.l d6,d6 ;Traverse to childnode
add.l d0,d0 ;Carry set = rightnode else left node
addx.l d3,d6 ;Left or rightbit
move.b (a2,d6.l),d2 ;If there is data!=0 we have reached a child node.
beq.b .t
move.b d2,(a1)+
subq.w #1,d4
bne.b .b
rts
NEXT TASK optimize my (untested) LZ cruncher :D
;Assumes LZ crunched data pointed in a0 (points to LZLENGTHPT)
;Destinationbuffer in a6
LZDECRUNCH:
movem.l (a0)+,a1-a3
move.l (a1)+,d7 ;how many lz codes to decrunch
.loop
move.b (a1)+,d0 ;
bpl.b .over
move.l a3,a4 ;raw-dataptr
neg.b d0 ;if negative just copy the bytes (not crunched)
bra.b .copyloop
.over
move.l a6,a4 ;outputbuffer
move.w (a2)+,d1 ;get offset
sub.l d1,a4
.copyloop
move.b (a4)+,(A6)+
subq.l #1,d0
bne.b .copyloop
dbf d7,.loop
rts
Tnx for helping me optimize. I restructured the hoffman table and removed more bytes. Now the loop is only 32 bytes. This routine is ideal for 4k decrunching, but since the hoffman table is a complete binary tree, it takes n! memory where n is the biggest hoffman code in the crunch.
SP_HOFFMANDECRUNCH:
moveq #1,d5
moveq #0,d3
.b moveq #1,d6
.t ror.l #1,d5
bpl.b .o
move.l (a0)+,d0
.o add.l d6,d6 ;Traverse to childnode
add.l d0,d0 ;Carry set = rightnode else left node
addx.l d3,d6 ;Left or rightbit
move.b (a2,d6.l),d2 ;If there is data!=0 we have reached a child node.
beq.b .t
move.b d2,(a1)+
subq.w #1,d4
bne.b .b
rts
NEXT TASK optimize my (untested) LZ cruncher :D
;Assumes LZ crunched data pointed in a0 (points to LZLENGTHPT)
;Destinationbuffer in a6
LZDECRUNCH:
movem.l (a0)+,a1-a3
move.l (a1)+,d7 ;how many lz codes to decrunch
.loop
move.b (a1)+,d0 ;
bpl.b .over
move.l a3,a4 ;raw-dataptr
neg.b d0 ;if negative just copy the bytes (not crunched)
bra.b .copyloop
.over
move.l a6,a4 ;outputbuffer
move.w (a2)+,d1 ;get offset
sub.l d1,a4
.copyloop
move.b (a4)+,(A6)+
subq.l #1,d0
bne.b .copyloop
dbf d7,.loop
rts
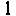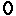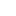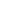
N! is wrong.
.
The Longest hoffman teoretic code for byte data is n=255. but normally the codes are not longer than 16 bit.
.
Precalc memory consumpiton where N= the longest huffman code in the chrunch.
n
---
\
/ 2^n
---
n=0
n=6 gives:
2^1 + 2^2 + 2^3 + 2^4 + 2^5 + 2^6 bytes.
.
The Longest hoffman teoretic code for byte data is n=255. but normally the codes are not longer than 16 bit.
.
Precalc memory consumpiton where N= the longest huffman code in the chrunch.
n
---
\
/ 2^n
---
n=0
n=6 gives:
2^1 + 2^2 + 2^3 + 2^4 + 2^5 + 2^6 bytes.
I'd really like to see how Blueberry's cruncher compares to something like UPX (which can pack Atari binaries). I guess a session with IDA is in order in the afternoon :)

btw, if you're aiming for a 4k cruncher wouldn't it be safe to replace the copyloop with something like:
.copyloop
move.b (a4)+,(A6)+
dbra d0,.copyloop
Or am I missing something here?
.copyloop
move.b (a4)+,(A6)+
dbra d0,.copyloop
Or am I missing something here?
sp: You left out 2^0. That's some memory trashing waiting to happen there. ;) Anyway your sum = 2^(n+1)-1
jsyk
jsyk

The first node in the tree will never have a child and is therefore not needed in the precalc table. :D in the 32 byte loop a2 point to (Hoffmantreebuffer - 2)
( 2^(n+1)-1 ) ' = 2^n
For hoffman precalc buffers I probobly end up using the chunkybuffer and maybe the screen buffer.
he-he. Like c64 productions, you can actully see the production is being decrunched.
ggn: The dbra instruction is 4 bytes and the same size as a subq.b and bxx.b
( 2^(n+1)-1 ) ' = 2^n
For hoffman precalc buffers I probobly end up using the chunkybuffer and maybe the screen buffer.
he-he. Like c64 productions, you can actully see the production is being decrunched.
ggn: The dbra instruction is 4 bytes and the same size as a subq.b and bxx.b
Have you people had a look at Ray/TSCC's lz77 and lz78 un/packer ? I don't know how it compares to hoffmantree but it's probably worth having a look.
sp^ctz, well at least I think that dbra performs faster on 68000 than sub/bne (I know it's not the case in 020+).
p01: I gave it a shot packing some data, about 1mb. Both were worse than Ice packer. I seem to remember that the best of the bunch is Mr. Ni!'s arj routines, (plus he optimised the unpacker to about 120 bytes :)
p01: I gave it a shot packing some data, about 1mb. Both were worse than Ice packer. I seem to remember that the best of the bunch is Mr. Ni!'s arj routines, (plus he optimised the unpacker to about 120 bytes :)
p01: Basicly my cruncher is 2 passes. First crunch with a LZ algorthm similiar to lz77. Then crunch with hoffman for the final output.
My target:
The decruncher should run fast on a mc68000 and be compact enough to be put in an intro. As far as I remember the Azure cruncher was a one pass aritmetric cruncher.
ggn: You are right the dbf is faster on 68000, so I probobly should change the code. On the 060 the sub bne is faster pecause of branch prediction (the branch is 0 cycles)
My target:
The decruncher should run fast on a mc68000 and be compact enough to be put in an intro. As far as I remember the Azure cruncher was a one pass aritmetric cruncher.
ggn: You are right the dbf is faster on 68000, so I probobly should change the code. On the 060 the sub bne is faster pecause of branch prediction (the branch is 0 cycles)
ggn: dbra is generally slower than subq + bxx.b, less flexible, and the same size anyway. Of course dbxx is conditional, which is also neat but not often useful.
sp^ctz: one thing I noticed though:
.loop
move.b (a1)+,d0 ;
[...]
.copyloop
move.b (a4)+,(A6)+
subq.l #1,d0
bne.b .copyloop
d0 is never initalised to zero (moveq #0,d0). You're using bytes all the way and then you do a subq.l #1,d0??? If you change that to subq.b #1,d0 then you have the advantage of not having to initialise d0. Also, dbra acts on .w content, so d0 needs to be initialised again. So, imo your current scheme, along with changing the subq to .b is the smallest solution.
.loop
move.b (a1)+,d0 ;
[...]
.copyloop
move.b (a4)+,(A6)+
subq.l #1,d0
bne.b .copyloop
d0 is never initalised to zero (moveq #0,d0). You're using bytes all the way and then you do a subq.l #1,d0??? If you change that to subq.b #1,d0 then you have the advantage of not having to initialise d0. Also, dbra acts on .w content, so d0 needs to be initialised again. So, imo your current scheme, along with changing the subq to .b is the smallest solution.
doom: at some odd points dbeq proved handy though :)
Doom: Dbf is faster on a plain 68000. And since there are dbxx instructions, I don't really see why it is less flexible. :)
:p
I tried Ray's LZ78: it's got a very decent pack ratio. i compacted a large 1 bitplane anim and it was just as good as ZIP with best compression. And that without Huffman (!).
I haven't tried it myself but that's what I thougt: it works well for data, and is really quick to unpack.
ggn: you are right. The code includes a bug :D. In the newest version I am orking on the offset bitlength and the lenght bitlength is not fixed width length as in this source.
My cruncher will probobly end up beeing:
1. Huffman
2. Lz
3. Aritmetric (sequential huffmann codes frequencies probabillities)
My cruncher will probobly end up beeing:
1. Huffman
2. Lz
3. Aritmetric (sequential huffmann codes frequencies probabillities)
Stingray: I said generally, didn't i :).. anyway his code starts like this:
;Mc68020 ++
dbxx is less flexible because it only counts on words, and the loop condition is always teh carry flag.
sp: Considered LZ + adaptive arithmetic coding?
I also think LZW is a reasonable candidate for a 4k cruncher. I could be very wrong of course.
;Mc68020 ++
dbxx is less flexible because it only counts on words, and the loop condition is always teh carry flag.
sp: Considered LZ + adaptive arithmetic coding?
I also think LZW is a reasonable candidate for a 4k cruncher. I could be very wrong of course.