
12 byte patch for speeding up tiny msdos intros
category: code [glöplog]
From the names i read upon my research in some forums, this is kind of old news to at least some of you, but maybe it is not so common knowledge that the patch is actually really small.
I am talking about "write combining", which in the usecase of tiny intros collects writing memory accesses to the VRAM to burst write it later for speeding up. I stumbled across "WC" when looking into, and thinking about the usefulness of, debug registers, control registers, test registers (which as of now just seem to be fancy storage alternatives that may save one byte or another) and finally model specific registers (MSR).
In short, you mark a specific memory region to have (or not have) WC and then things run faster. There is really a lot about this to find online so i come directly to the point:
This sets WC for the segment A0000 (to B0000). I tested that on FreeDos on my Samsung R519 notebook with a Intel Intel(R) Core(TM)2 Duo CPU T6500 and a NVIDIA G105M.
This works on Pentium and higher, DOSBOX does not recognize the WRMSR command ...
I did a simple test of repeatedly writing pixels to the screen, with a flashing animation which does 256 screens per flash, and because i am lazy, just used https://www.all8.com/tools/bpm.htm to measure the speed ^^
without speedup : 40
with speedup : 149
Yes, that's 372% performance.
Of course, the boost becomes a lot smaller when using a lot of calculations between pixel writes. I tested again with the tiny intro Lucy 64b.
without speedup : 76
with speedup : 98
That's 130% performance.
I tested again with the known program MTRRLFBE instead of my own patch and the numbers didn't change, so i guess i did everything right.
So, where did i get the information from?
https://www.felixcloutier.com/x86/wrmsr
Number 0x259 from here and also in the Intel Manual
Pages 3137-3140 of "Intel® 64 and IA-32 Architectures Software Developer’s Manual Combined Volumes: 1, 2A, 2B, 2C, 2D, 3A, 3B, 3C, 3D, and 4" ( here )
General Video about Graphics Boost for DOS : here
On bare DOS you may need "HDPMI", found here.
Since the technique itself seems fairly common, i'm happy to get more insights about the whole topic or comments to get more speed or shrink the patch size =)
I am talking about "write combining", which in the usecase of tiny intros collects writing memory accesses to the VRAM to burst write it later for speeding up. I stumbled across "WC" when looking into, and thinking about the usefulness of, debug registers, control registers, test registers (which as of now just seem to be fancy storage alternatives that may save one byte or another) and finally model specific registers (MSR).
In short, you mark a specific memory region to have (or not have) WC and then things run faster. There is really a lot about this to find online so i come directly to the point:
Code:
mov cx,0x259
mov eax,0x01010101
pop dx ;=0, save=CDQ, 1b more
wrmsrThis sets WC for the segment A0000 (to B0000). I tested that on FreeDos on my Samsung R519 notebook with a Intel Intel(R) Core(TM)2 Duo CPU T6500 and a NVIDIA G105M.
This works on Pentium and higher, DOSBOX does not recognize the WRMSR command ...
I did a simple test of repeatedly writing pixels to the screen, with a flashing animation which does 256 screens per flash, and because i am lazy, just used https://www.all8.com/tools/bpm.htm to measure the speed ^^
Code:
; comment out for no speedup
mov cx,0x259
mov eax,0x01010101
pop dx ;=0, save=CDQ, 1b more
wrmsr
mov ax,0x13
int 0x10
push 0xa000
pop es
X: stosb
loop X
mov al,16
inc bl
test bl,0x80
jnz Z
dec ax
Z: jmp short Xwithout speedup : 40
with speedup : 149
Yes, that's 372% performance.
Of course, the boost becomes a lot smaller when using a lot of calculations between pixel writes. I tested again with the tiny intro Lucy 64b.
without speedup : 76
with speedup : 98
That's 130% performance.
I tested again with the known program MTRRLFBE instead of my own patch and the numbers didn't change, so i guess i did everything right.
So, where did i get the information from?
https://www.felixcloutier.com/x86/wrmsr
Number 0x259 from here and also in the Intel Manual
Pages 3137-3140 of "Intel® 64 and IA-32 Architectures Software Developer’s Manual Combined Volumes: 1, 2A, 2B, 2C, 2D, 3A, 3B, 3C, 3D, and 4" ( here )
General Video about Graphics Boost for DOS : here
On bare DOS you may need "HDPMI", found here.
Since the technique itself seems fairly common, i'm happy to get more insights about the whole topic or comments to get more speed or shrink the patch size =)

MOV EAX,0x01010101 can be one byte shorter (assuming SI=0x100):
You need to set all of EDX (not only DX), so CDQ or MOV EDX,EAX is the way to go. (Or RDMSR.)
Code:
inc si | push si | push si | pop eaxYou need to set all of EDX (not only DX), so CDQ or MOV EDX,EAX is the way to go. (Or RDMSR.)

I felt there was a shorter way, thanks :) I am assuming top of EDX is already zero, i would of course revert to CDQ if the code fails (and it will fail on random values in EDX)
Quite interesting, didn't know that ! Does that also enhance speed for true colour modes like 640x480 and STOSD under FreeDOS despite the page flipping required in those modes ?

@Kuemmel Yes it does, and that's where the speedup get's real because with rising resolution, the pixel pushing requires more time in relation to calculation. I didn't benchmark that yet. Also there is there "normal" way to do it, in contrast to "IA32_MTRR_FIX16K_A0000" which i am using now. You would specify the real 32 bit adress of the LFB (VESA). You can test it with the MTRRLFBE tool linked above (Look into the video for parameters) I didn't yet delve into that ;)
Another note, of course the maximum speed up is achieved when having double buffering. In case there is place for that, that's a real boost =)
Another note, of course the maximum speed up is achieved when having double buffering. In case there is place for that, that's a real boost =)
Here are my results for 640x480 TrueColor Recursive RayTracing,
the fx from my seminar
Desktop PC with nVidia 1050
Notebook, integrated gfx
For the other speedup I tried this code:
You can read about this at Ped's source code:
HEART IN LOVE
These speedup is more powerfull under Dosbox!
And one more thing:
you may noticed already if you write your temp vars to the address 100H, you may get a code cache conflict easily... and your code will run very slowly,
(the interesting thing, if i run the code from volkov commander, the problem never appear)
So if you want to MOV [SI],AX, first change SI, like
the fx from my seminar
Desktop PC with nVidia 1050
Quote:
no speedup
318 timer ticks
15,3792472024 RDTSC EDX,EAX
write combine
166 ticks
8,1419034369 RDTSC EDX,EAX
lower fpu precision
310 timer ticks
15,2191496823 RDTSC EDX,EAX
both speedups
161 ticks
8,163713452 RDTSC EDX,EAX
Notebook, integrated gfx
Quote:
no speedup
494 timer ticks
15,514199760 RDTSC EDX,EAX
write combine
279 ticks
8,2305766180 RDTSC EDX,EAX
lower fpu precision
478 timer ticks
14,2801465456 RDTSC EDX,EAX
both speedups
264 ticks
8,296854544 RDTSC EDX,EAX
For the other speedup I tried this code:
Code:
CALL @F
DW 0x06BF
@@:
POP BX
FLDCW [BX]
You can read about this at Ped's source code:
HEART IN LOVE
These speedup is more powerfull under Dosbox!
And one more thing:
you may noticed already if you write your temp vars to the address 100H, you may get a code cache conflict easily... and your code will run very slowly,
(the interesting thing, if i run the code from volkov commander, the problem never appear)
So if you want to MOV [SI],AX, first change SI, like
Code:
MOV SI,0A000H
MOV AX,SI

@Tomcat thanks for the detailed benchmarking =) And also for the FPU speed up trick, that went under my radar. So, "write combine" can speed up real hi res intros by a factor of 2 on real hardware, that's awesome to know. I wonder what else is there in our weaponry which gives speed boosts for the mere price of a few bytes.
nice! i'm also thinking on writing a TSR for on-the-fly VGA write combining switching, as Mode-X/16 color modes (tbmp VGA latches/graphic controller/ALU magic) are entirely incompatible with write combine but it's handy at other times for mode0x13 stuff :)
the only issue here is DOS extender/DPMI applications, as the would not allow you to fiddle with MSR so easily
the only issue here is DOS extender/DPMI applications, as the would not allow you to fiddle with MSR so easily
Thumbs up for starting this thread.

I was aware about this, but just running tools like Fastvid or MTRRLFBE. Never knew how to enable it with my own code or more info about what it does.
I think it's support from Pentium Pro and on. I always run it on start up and does big difference especially in high resolutions.
I think it's support from Pentium Pro and on. I always run it on start up and does big difference especially in high resolutions.
I was noticing some interesting stuff with it.
Before that, I used to rep stosd, made a difference if you write 8bits, 16 or 32bits at once.
But after enabling it, a rep stosb is same fast as rep stosd. Makes sense, if it collects the writes and bursts them out later.
Then, I write byte per byte for vertical columns (e.g. for wolfenstein or voxel). At that point it lost it's effectiveness, I was as slow as writting individual bytes, not packing and writting 32bit at once. I guess it makes sense, you need to write linearly if possible.
One more interesting thing I noticed, games that use Mode-X tricks to write 2-3-4 pixels at once (by changing that mask register), will sometimes draw garbage when write combining is enabled. Doom for example, the border around the game when you make the screen smaller, comes out as garbage. But the game area is correct. Why is that? I guess, when writting the border background, a byte is written, the switch frequently the mask register to select which pixel to write for the byte. But WC will keep the writes and write them later when the mask register can be at any arbitrary state, not the originals intended per byte written. While the game are rendering (of walls, floors and sprites) from what I remember, would minimise the mask register changes, would render all columns at 0,4,8,etc then switch the mask, render the 1,5,9, etc. WC is agnosting of what mode-x mask register changes while you were writing the bytes, will just burst the pixels all at once later. Wolfesntein 3D must be different, everything (border and game area) come garbled.
Before that, I used to rep stosd, made a difference if you write 8bits, 16 or 32bits at once.
But after enabling it, a rep stosb is same fast as rep stosd. Makes sense, if it collects the writes and bursts them out later.
Then, I write byte per byte for vertical columns (e.g. for wolfenstein or voxel). At that point it lost it's effectiveness, I was as slow as writting individual bytes, not packing and writting 32bit at once. I guess it makes sense, you need to write linearly if possible.
One more interesting thing I noticed, games that use Mode-X tricks to write 2-3-4 pixels at once (by changing that mask register), will sometimes draw garbage when write combining is enabled. Doom for example, the border around the game when you make the screen smaller, comes out as garbage. But the game area is correct. Why is that? I guess, when writting the border background, a byte is written, the switch frequently the mask register to select which pixel to write for the byte. But WC will keep the writes and write them later when the mask register can be at any arbitrary state, not the originals intended per byte written. While the game are rendering (of walls, floors and sprites) from what I remember, would minimise the mask register changes, would render all columns at 0,4,8,etc then switch the mask, render the 1,5,9, etc. WC is agnosting of what mode-x mask register changes while you were writing the bytes, will just burst the pixels all at once later. Wolfesntein 3D must be different, everything (border and game area) come garbled.
Are you sure the garble is from writing only, and not read/write copying? It works like this: you read one byte and write one byte over the bus, but in the VGA, 32 bits get copied. The 3 extra bytes are never transferred over the bus. This only works with byte-size loads and stores, because inside the VGA the ”latches” (or whatever they’re called) are only 32 bits wide.
i remember having had "write combing" (sic) as a flag in a bios back then. obviosuly enabling this had massive impact on performance. I wonder whether this bios setting governed the general availa bility of that feature, or maybe it was a "global force enable"? in other words: what are the disadvantages or problems resulting from using this? there must be a tradeoff, otherwise it wouldn't be optional.
Instructions don’t do exactly what they’re supposed to.
@jco
"For example, a Write/Read/Write combination to a specific address would lead to the write combining order of Read/Write/Write which can lead to obtaining wrong values with the first read (which potentially relies on the write before)." - source
The next thing that comes to mind is a cellular automata effect like amoeba, depending on how you implement it, it works slightly different with WC or even not at all as expected.
@optimus, thanks for the insights =)
@wbc, you are one of the names i saw in the forums ;) why would MTRRLFBE even need DPMI on real hardware? The tiny patch just works without it. Seems i fail to understand something here ^^
"For example, a Write/Read/Write combination to a specific address would lead to the write combining order of Read/Write/Write which can lead to obtaining wrong values with the first read (which potentially relies on the write before)." - source
The next thing that comes to mind is a cellular automata effect like amoeba, depending on how you implement it, it works slightly different with WC or even not at all as expected.
@optimus, thanks for the insights =)
@wbc, you are one of the names i saw in the forums ;) why would MTRRLFBE even need DPMI on real hardware? The tiny patch just works without it. Seems i fail to understand something here ^^
Quote:
why would MTRRLFBE even need DPMI on real hardware? The tiny patch just works without it. Seems i fail to understand something here ^^
yup, while you are running in real mode (and in case of EMM386/QEMM, in V86, can't remember if they allow to fiddle with MSRs though), nothing can restrict you from accessing MSRs and DPMI/whatever is not required at all (and that's why your patch works fine :)
but in case of TSR doing the same task (i.e. hooking INT 0x10 and switching write combining state depending on mode being set) your code can (if being asserted by protected mode application) actually running in V86 mode, where WRMSR\RDMSR are virtualized and either handled correctly or causing a general protection fault, depending on DPMI server/DOS extender design :)
TomCat tested my codegrinder true colour versions (linky) with WC, FPU and SSE...none of them showed any speedup...I wonder why...may be if there's too much other stuff going on between writing the next byte/word to the screen, so it just decides somehow to write it without speedup...?
Reminds me on ryg's headline about WC though it was in another context ;-)
Reminds me on ryg's headline about WC though it was in another context ;-)
If EDX=0000????, EAX=0 and ECX=0xFF, this is even shorter:
It sets EDX to 0x1, which just enables write combining for B0000..B3FFF.
But neither WinXP nor DOSBox clear the top 16 bits of registers between program runs, ymmv.
Code:
cwd | inc dx | div ecxIt sets EDX to 0x1, which just enables write combining for B0000..B3FFF.
But neither WinXP nor DOSBox clear the top 16 bits of registers between program runs, ymmv.
@rrrola, dude that's hilarious and beautiful. How did you even get this idea :D Didn't work on my notebook though ... i have another weird idea, which so far just works on dosbox, where it's useless ^^ (it's also not shorter)
debug view
@Kuemmel I'm not even sure that your link was so out of context : "This means all pending write-combining buffers get flushed, and then the read is performed without any cache" (from that article) which would explain why so far, i couldn't create a counter example to show that WC can fail badly. Unless the "only" drawback would be less performance than without WC, but i don't know enough about that.
Code:
pop ss | mov sp,6a1eh | popad debug view
@Kuemmel I'm not even sure that your link was so out of context : "This means all pending write-combining buffers get flushed, and then the read is performed without any cache" (from that article) which would explain why so far, i couldn't create a counter example to show that WC can fail badly. Unless the "only" drawback would be less performance than without WC, but i don't know enough about that.
if I sped up pluto128 it would have runned too fast. i wouldn't want that :) anyways nice to see you figure out new things even though i dont understand any of it.

{kind=link}
@rudi don't worry about that. To prevent running too fast you need only one extra byte for the instruction
Code:
HLTis WC the thing or not? I had more tests with my truecolor intros,
and now I can report it, that not everything is gold which is shining.
:)
So let's look at the intros one by one
1. RT
https://youtu.be/V_ntnQKemWA?t=2766
2-3x speed bonus, 318vs116, 494vs264
2. CODEGRINDER TRUECOLOR
https://youtu.be/zcFwVv2HyeA
nothing or 4-5x speed bonus?!, 103vs103, 245vs49
usually nothing but in only one case on my laptop with integrated VGA
I was able to measure very good result (without volkov commander!)
3. CODEGRINDER TRUECOLOR
Same intro but the FPU version
no speed bonus, 257vs257, 161vs161
4. COLORFUL
https://youtu.be/aNX2iP2emLI
no WC speed bonus, 610vs583, 591vs582
(little achievement by the FPU tweak)
5. BRAINS CANYON
https://youtu.be/ghI6B_hPT5c
4-5x speed bonus or less?, 1114vs248, 803vs616
after this I've tried to replace REP MOVSW to REP MOVSD in the 1st intro,
but the result not changed.
6. POKEBALL
https://youtu.be/wJOD2GrF1U4
3-4x speed bonus!, 174vs53, 127vs46
7. SEASHELL
https://youtu.be/Y84dE6MOdhE
no WC speed bonus, 243vs240, 265vs263
(little achievement by the FPU tweak)
This is very similar code to POKEBALL, but this time we are reading from the vmem.
what more, we are writing only one sphere/frame, not the whole screen.
So I think ryg's article has some rights.
and with some restrictions we can reach more than 4 times speedup!
- 1st: not to read from the WC mem, 2nd: use regular STOS instructions.
foot note:
I don't know why VC matter, maybe the intro runs in different memory segment
with and without the Volkov Commander.
and now I can report it, that not everything is gold which is shining.
:)
So let's look at the intros one by one
1. RT
https://youtu.be/V_ntnQKemWA?t=2766
Code:
MOV CX,640/5*4/2
REP MOVSW
2-3x speed bonus, 318vs116, 494vs264
2. CODEGRINDER TRUECOLOR
https://youtu.be/zcFwVv2HyeA
Code:
movd dword[es:di],xmm1
nothing or 4-5x speed bonus?!, 103vs103, 245vs49
usually nothing but in only one case on my laptop with integrated VGA
I was able to measure very good result (without volkov commander!)
3. CODEGRINDER TRUECOLOR
Same intro but the FPU version
Code:
stosb
dec ch
jnz rgb_loop
inc di
no speed bonus, 257vs257, 161vs161
4. COLORFUL
https://youtu.be/aNX2iP2emLI
Code:
VideoPtr:
FISTP WORD [ES:BX+0FFFCH]
INC BX
JPO loop3x
SUB WORD [BYTE SI+(VideoPtr+3-264)],DX
no WC speed bonus, 610vs583, 591vs582
(little achievement by the FPU tweak)
5. BRAINS CANYON
https://youtu.be/ghI6B_hPT5c
Code:
MOV CX,128
REP MOVSD
4-5x speed bonus or less?, 1114vs248, 803vs616
after this I've tried to replace REP MOVSW to REP MOVSD in the 1st intro,
but the result not changed.
6. POKEBALL
https://youtu.be/wJOD2GrF1U4
Code:
STOSB
INC BX
JPO loop3x
SUB DI,SP
3-4x speed bonus!, 174vs53, 127vs46
7. SEASHELL
https://youtu.be/Y84dE6MOdhE
Code:
CMP [ES:DI+3],DL
JA pixelok
loop3x:
STOSB
INC BX
JPO loop3x
XCHG AX,DX
STOSB
skip:
SUB DI,SP
no WC speed bonus, 243vs240, 265vs263
(little achievement by the FPU tweak)
This is very similar code to POKEBALL, but this time we are reading from the vmem.
what more, we are writing only one sphere/frame, not the whole screen.
So I think ryg's article has some rights.
and with some restrictions we can reach more than 4 times speedup!
- 1st: not to read from the WC mem, 2nd: use regular STOS instructions.
foot note:
I don't know why VC matter, maybe the intro runs in different memory segment
with and without the Volkov Commander.
Volkov Commander! Must be a distant relative of mine.
One more important note, that the upper half of ECX must be zero... otherwise your machine will freeze.
I made a test pack with 256b intros for write combine. After DOS reboot you can run a batch file and you will get a text file for result. It is available on request (email prefered).
Here are my final results in table format:
(ECX bug fixed since my previous post).
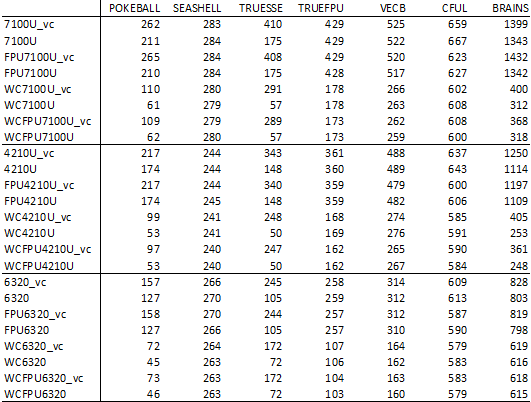
Some of the intros run nearly constant speed, like SEASHELL or COLORFUL.
here WC doesn't help at all...
reasons could be: not filling the whole screen, or reading from vmem, or drawing too slow.
Other intros gain benefit of WC. The speedup is: from 2.0x to 4,3x !!!
The other thing which shown in the table... The running speed how different can be with or without VolkovCommander :-(
(and also... different CPUs could have different behavior)
I made a test pack with 256b intros for write combine. After DOS reboot you can run a batch file and you will get a text file for result. It is available on request (email prefered).
Here are my final results in table format:
(ECX bug fixed since my previous post).
Some of the intros run nearly constant speed, like SEASHELL or COLORFUL.
here WC doesn't help at all...
reasons could be: not filling the whole screen, or reading from vmem, or drawing too slow.
Other intros gain benefit of WC. The speedup is: from 2.0x to 4,3x !!!
The other thing which shown in the table... The running speed how different can be with or without VolkovCommander :-(
(and also... different CPUs could have different behavior)
@yzi: The garble appears on Doom/Wolf because of the mode x tricks seemingly. They had the pattern of each 4 pixels.
https://www.youtube.com/watch?v=4BL-nctn0C0
https://www.youtube.com/watch?v=4BL-nctn0C0